OpenAI a dévoilé un nouveau modèle pour ses produits, qui sera accessible aux utilisateurs vers la fin de janvier 2025 : il s’appelle o3 (nous avons apparemment sauté o2), et il promet un pas de plus significatif dans le raisonnement de l’IA. Selon ses développeurs, il rendra des outils comme ChatGPT meilleurs que jamais en matière de programmation et de résolution de problèmes mathématiques.
Le PDG d’OpenAI, Sam Altman, a décrit o3 comme “incroyablement intelligent” dans la vidéo annonçant le modèle, diffusée dans le cadre de la promotion “12 Jours d’OpenAI” de sa société pendant la période des fêtes. Le modèle subit une variété de tests de sécurité avant son lancement complet, probablement d’abord uniquement pour les utilisateurs payants de ChatGPT Plus.
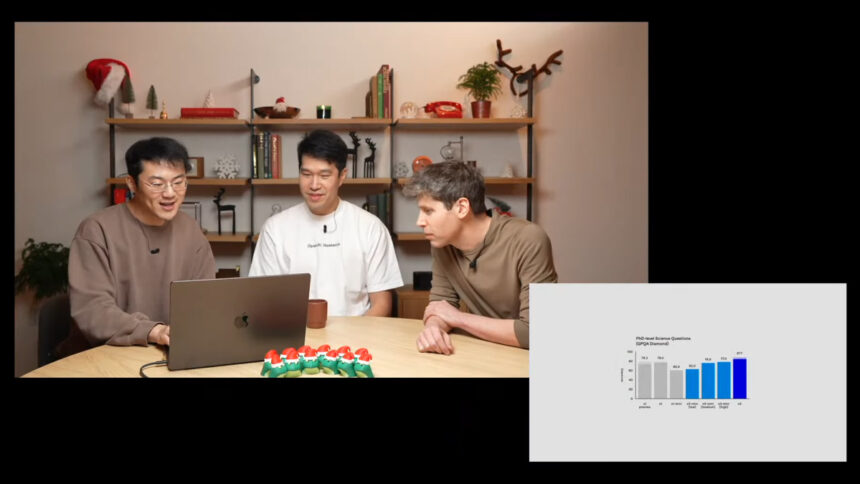
Le modèle o3 est plus de 20 % meilleur que le précédent modèle o1 en matière de codage, selon le benchmark vérifié SWE-bench, affirme OpenAI. Il obtient également de bons résultats sur les problèmes mathématiques et scientifiques, du moins selon les tests de référence—à l’instar de o1, le modèle o3 est formé pour penser et raisonner avant de répondre, testant rigoureusement ses réponses pour en garantir l’exactitude. OpenAI publiera également un modèle plus petit et plus rapide, le o3-mini, en même temps que la mise à jour principale.
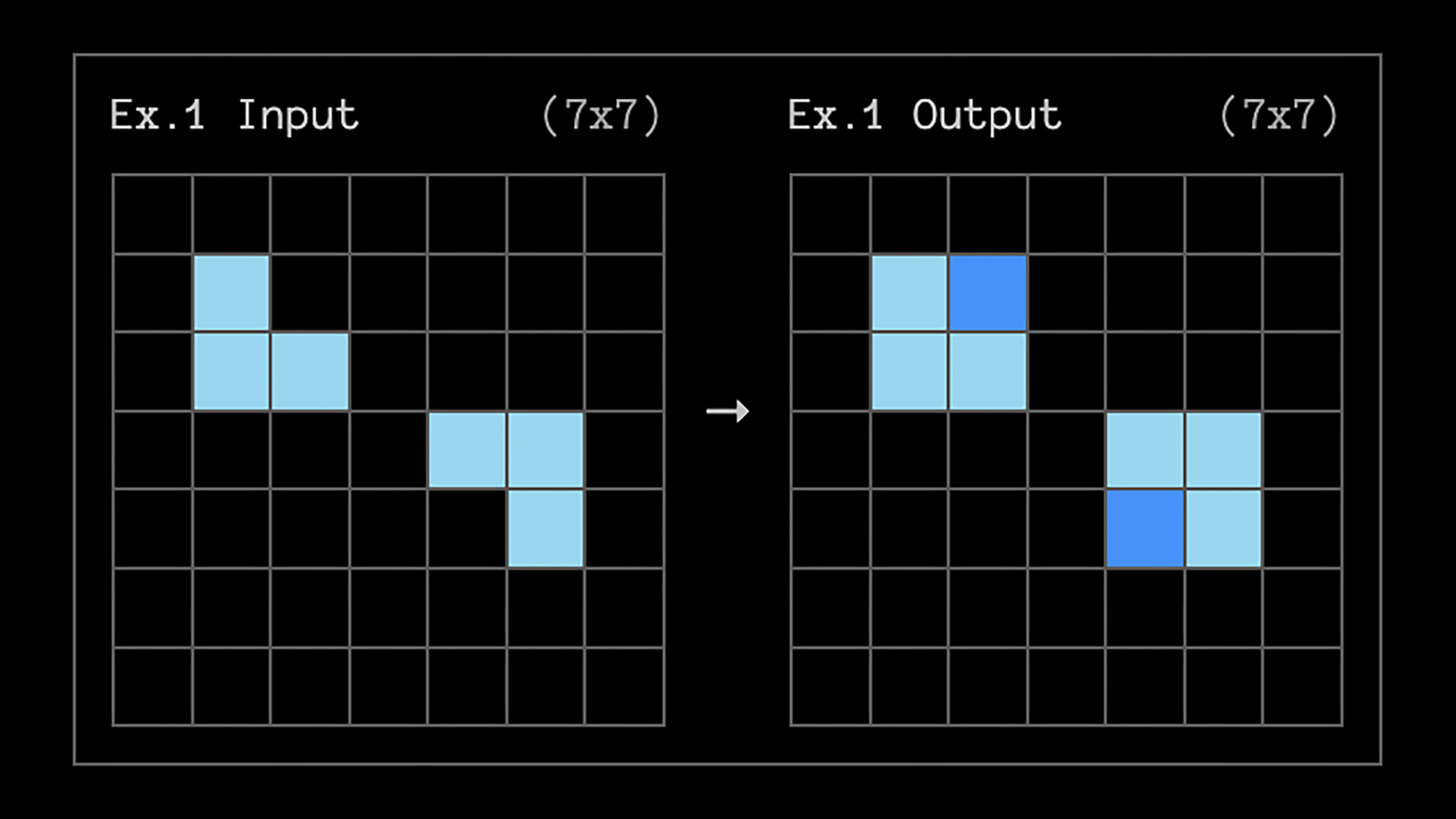
Crédit : ARC
Nous ne saurons pas à quel point o3 est performant tant que les utilisateurs ne pourront pas réellement l’essayer, mais nous avons déjà une idée de ce que o3 peut faire car il a été testé contre le bien connu Corpus d’Abstraction et de Raisonnement (ARC), conçu pour suivre les progrès de l’IA vers l’Intelligence Artificielle Générale (AGI)—le point quelque peu controversé où les capacités cognitives de l’IA dépassent celles des humains.
Ce défi demande à l’IA de trouver de nouvelles approches pour résoudre des problèmes, plutôt que de simplement s’appuyer sur sa mémoire, et implique une série de tâches visuelles à compléter. Elle doit faire correspondre des motifs dans des grilles colorées, des exercices censés être faciles à réaliser pour les gens sans aucune formation, mais difficiles à comprendre pour l’IA.
Dans les limites de la puissance de calcul du test ARC, o3 a obtenu un score de 75,7%. C’est bien au-dessus des 5 % atteints par le modèle GPT-4o, actuellement le meilleur modèle ChatGPT disponible pour les utilisateurs gratuits. Bien que nous soyons encore loin de l’AGI (le modèle reste en dessous des scores humains et n’a pas pu compléter toutes les tâches), c’est une avancée impressionnante.
Que pensez-vous jusqu’à présent ?
Crédit : Cours Technologie
“Le nouveau modèle o3 d’OpenAI représente un bond significatif dans la capacité de l’IA à s’adapter à de nouvelles tâches,” écrit François Chollet, l’ingénieur logiciel qui a conçu le test ARC. “Ce n’est pas simplement une amélioration incrémentielle, mais une véritable percée, marquant un changement qualitatif dans les capacités de l’IA par rapport aux limitations antérieures des LLM.”
Prévisiblement, OpenAI n’a pas abordé les besoins énergétiques de l’IA, l’éthique de la formation de l’IA sur des données accessibles au public qui peuvent être protégées par des droits d’auteur, ou la tendance de ces modèles à halluciner des réponses incorrectes—bien que les erreurs devraient être moins fréquentes grâce au temps de réflexion supplémentaire d’o3, elles ne seront pas éradiquées. Ce que la société a mentionné, c’est une expansion de son programme de tests de sécurité, conçu pour prévenir l’utilisation malveillante de ces modèles.
La capacité des modèles d’IA à “penser” ou “raisonner” véritablement—ou du moins à tenter une approximation de ces capacités humaines—continuera sans aucun doute d’être discutée à mesure que le développement de l’IA progresse. Google vient également de dévoiler son modèle Gemini 2.0, qui apporte une amélioration du raisonnement.








