Il n’y a rien de pire que d’ouvrir un PDF et de réaliser que vous ne pouvez ni utiliser la fonction de recherche ni surligner le texte. Cela se produit généralement lorsqu’un PDF a été créé en scannant un document papier : c’est juste une série d’images. La plupart des logiciels de numérisation modernes utilisent la reconnaissance optique de caractères (OCR) pour que les mots soient à la fois recherchables et sélectionnables, mais parfois, vous tomberez sur des documents où cela n’a pas été fait.
Dans ces cas, le logiciel libre et open source OCRmyPDF est parfait à avoir sous la main. Il s’agit d’une application en ligne de commande qui convertit rapidement tout fichier PDF en un fichier PDF/A avec reconnaissance optique de caractères. Cela signifie que vous pourrez rechercher le texte. Encore mieux, c’est complètement gratuit.
L’installation de l’application se fait de préférence avec votre gestionnaire de paquets sur les appareils Linux et en utilisant Homebrew sur Mac. Les utilisateurs de Windows peuvent techniquement installer l’application en installant Python et quelques autres dépendances ; renseignez-vous à ce sujet si vous êtes prêt à chercher.

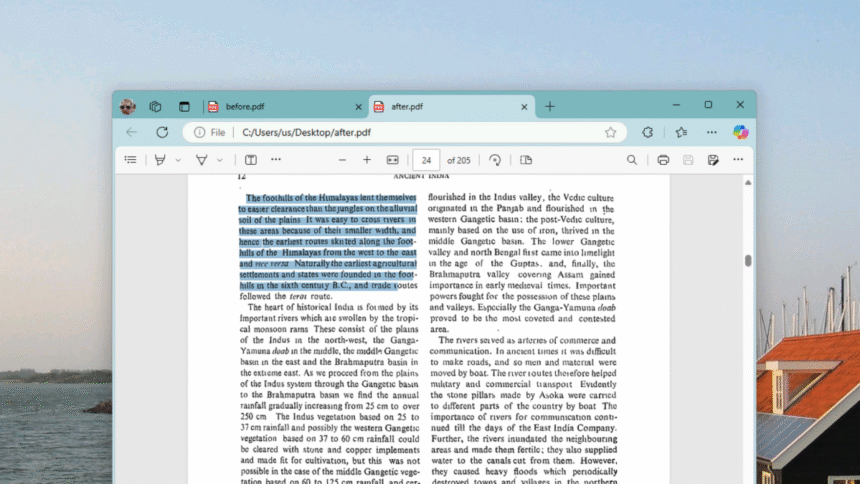
Une fois l’application configurée, vous pouvez l’utiliser en tapant ocrmypdf suivi du nom du document auquel vous voulez ajouter l’OCR à, puis le nom du document que vous souhaitez créer. Par exemple, ocrmypdf before.pdf after.pdf prendra “before.pdf”, ajoutera la reconnaissance de caractères, puis créera un nouveau document appelé “after.pdf”.
Le processus prendra un certain temps, en fonction de la taille du document, et il pourrait ne pas être entièrement précis si la qualité de l’image est faible. Ceci dit, j’ai trouvé que cela faisait un assez bon travail même avec les PDFs les plus anciens et mal compressés que j’ai pu trouver.
Que pensez-vous jusqu’à présent ?








